Database index is a something that summerizes the actual table you assign on top of it
-- summerizing the names of imployuees using and index
CREATE INDEX employees_name on employees(name);The most obvious example of an index is the phone book index, you summerize the whole book (table) using the first character of names.
It’s like a special type of data structure that store some information about the table it summerizes, these information can lead to huge performance optimizations in reading the table’s data.
You find quickly what you want
— A Primary key has an index by default
Examples with explanations
SELECT id
FROM Employee
WHERE id = 1000that will be executed really fast, you search a column that has an index on that column (id) and you return that it, so you are not even touching the actual table anyway
Index Only Scan using employees_pkey on employees (cost=0.42..4.44 rows=1 width=4) (actual time=0.028..0.045 rows=1.00 loops=1)
Index Cond: (id = 1000)
Heap Fetches: 0
Index Searches: 1
Buffers: shared hit=4
Planning Time: 0.084 ms
Execution Time: 0.100 ms
Notice the Heap Fetches: 0 means no table access at all, just I used the index of the column (id) and because id is on the index I will use it and never touch the table
Planning Time: 0.084 ms: means the time needed from the engine to decide should I scan the whole table or there’s some index makes things simpler
SELECT name
FROM Employee
WHERE id = 1000You can expect to touch the table here, name is not within the index there’s just id
so it may be a little slower than select id
TIP
Notice the usage of the index “Index Only Scan using employees_pkey on employees ”
TIP
We need to avoid going to the table as much as possible, it’s the heaviest thing
select id
from employees
where name = "Zs"Gather (cost=1000.00..11310.94 rows=6 width=4) (actual time=4.735..82.013 rows=26.00 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=5102
-> Parallel Seq Scan on employees (cost=0.00..10310.34 rows=2 width=4) (actual time=1.758..39.373 rows=8.67 loops=3)
Filter: (name = 'Zs'::text)
Rows Removed by Filter: 333325
Buffers: shared hit=5102
Planning:
Buffers: shared hit=6 dirtied=1
Planning Time: 0.131 ms
Execution Time: 82.589 ms
No index on name so the engine uses parallel sequential scanning (scan the whole table).
notice the huge difference in the Execution Time between the previous query and the first query where we search by id, there’s an index on id so the planner decides to use it and this makes the query much faster than executing the last query scanning the whole table without any index.
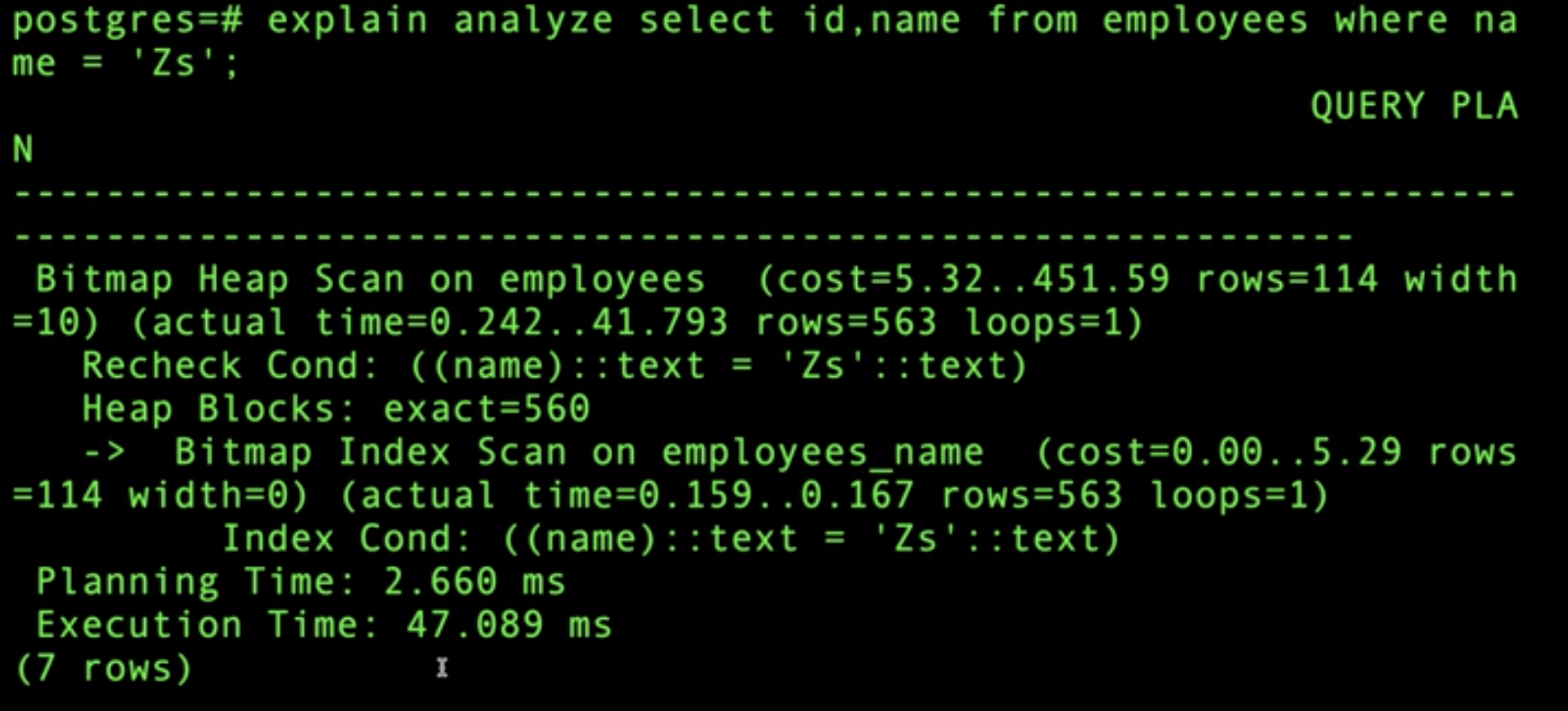
After making an index on the name column and executing the same query:
Almost 50% performance increase after indexing
NOTE
The word
parallelreflects the 2 lines:
- Workers Planned: 2
- Workers Launched: 2
Postgres tries to make things faster even for sequential scanning by using multi threading and parallelism by spawning 2 workers each search for the data in a different portion of the table
Warning
using
like '%Zs%'is a really bad practice as even there’s an index on the column the engine still needs to sequentially scan the whole table.using
select *is also a bad practice, imagine you only need 2 or 3 columns, some of them has their own indexes so why to go the actual table and get the whole columns, what about on of the column is a blob store ?
Final Note
Having an index doesn’t mean database will always use it, It’s going to plan and according to the planner will decide to use the index or not. You are as an engineer should give hints to the database to whether using the indexs or not.