It’s about splitting the data itself while maintaining the database schema Again you can split the data into different database server within the same node if the node capacity affords good storage. Imaging it’s just about the indexing become too large to scan or load it into memory, we can use part of it by sharding the data so for 2 shards the index almost divided by 2 okay that’s good until we reach the limit of node’s resources the the usual way we use different database servers on different nodes.
Note that every shard has the same schema
The main idea is to choose a column to be use as the partitioning key, depending on the value of that column we will determine on which shard this data row will be stored.
2 ways of horizontal sharding
- key-range based
- hash-based
key range
key: Customer_Id idea: form 1 → x to be on shard-1 and from x → y to be on shard-2 and so on
the application need to maintain this mapping in a cache to know where to get a put new data.
Also the primary key is unique across all shards, so there’s no primary key separated for each shard.
Pros: Range queries become easier to implement but only using the partitioning key
Cons: some shards can be easily overloaded if the key not chosen properly
Hash based
Partition = Hash(key) % n , where n is the number of partitions
You choose:
- partitioning key
- Hash function
Pros: data will be uniformly distributed across shards
cons: range queries can’t be performed easily on the partitioning key
Warning
The huge problem with the
mod napproach is that it’s not resilient against adding or removing nodes from the cluster
Imagine you have 4 shards, then now the data becomes large and you want to add another partition now n = 5 we need to redistribute the data according to Hash(key) % 5 instead of Hash(key) % 4 , also what if one of the shards goes down and assume the data of this dead shard in persisted we need to redistribute the data again according to Hash(key) % 3 . Lot’s of headache
A great solution to the modulo n problem is using “Consistent Hashing” where nodes are distributed on a circle called “hash ring” and the items add according to their hashes this makes it easy to scale horizontally , increase the throughput and improves latency but can lead to unbalanced load if the virtual nodes technique not used.
Look at this article to quick recap Hello interview consistent hashing
but to summarize:
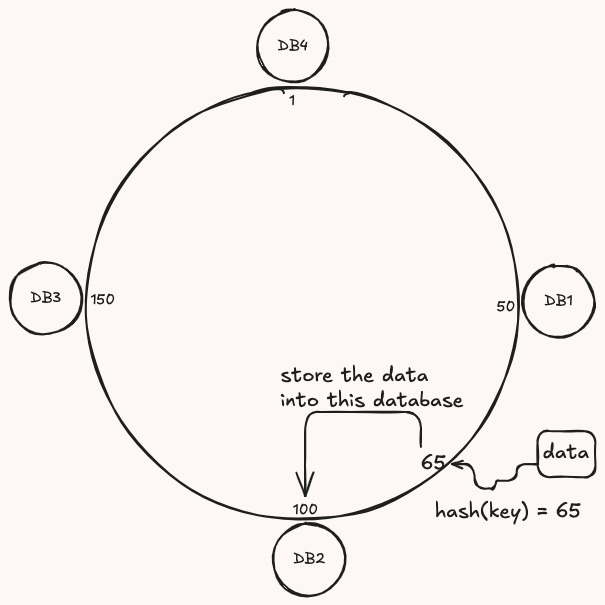 The databases are distributed using a hash function on the hash ring
The databases are distributed using a hash function on the hash ring
hash(db_id) = Value
using the same hash function, get the hash value according to the partitioning key
hash(Employee_Id) = Value
Lookup the value on the ring and put the data on closest database clock wise
adding new node
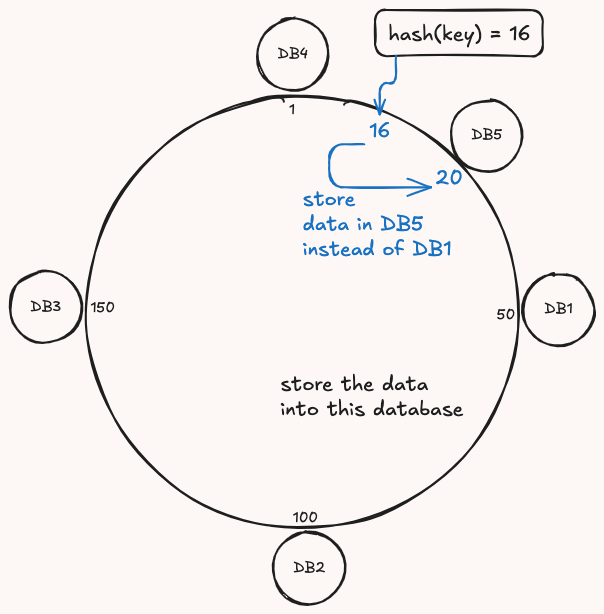 simply works as usual no updates
you hash the key and if the value just before the new node position add the data to that node
simply works as usual no updates
you hash the key and if the value just before the new node position add the data to that node
removing nodes
if DB1 has been removed then the whole data stored on DB1 will be moved to DB2 but because we need to ensure balanced sharding the idea of virtual nodes solve this problem
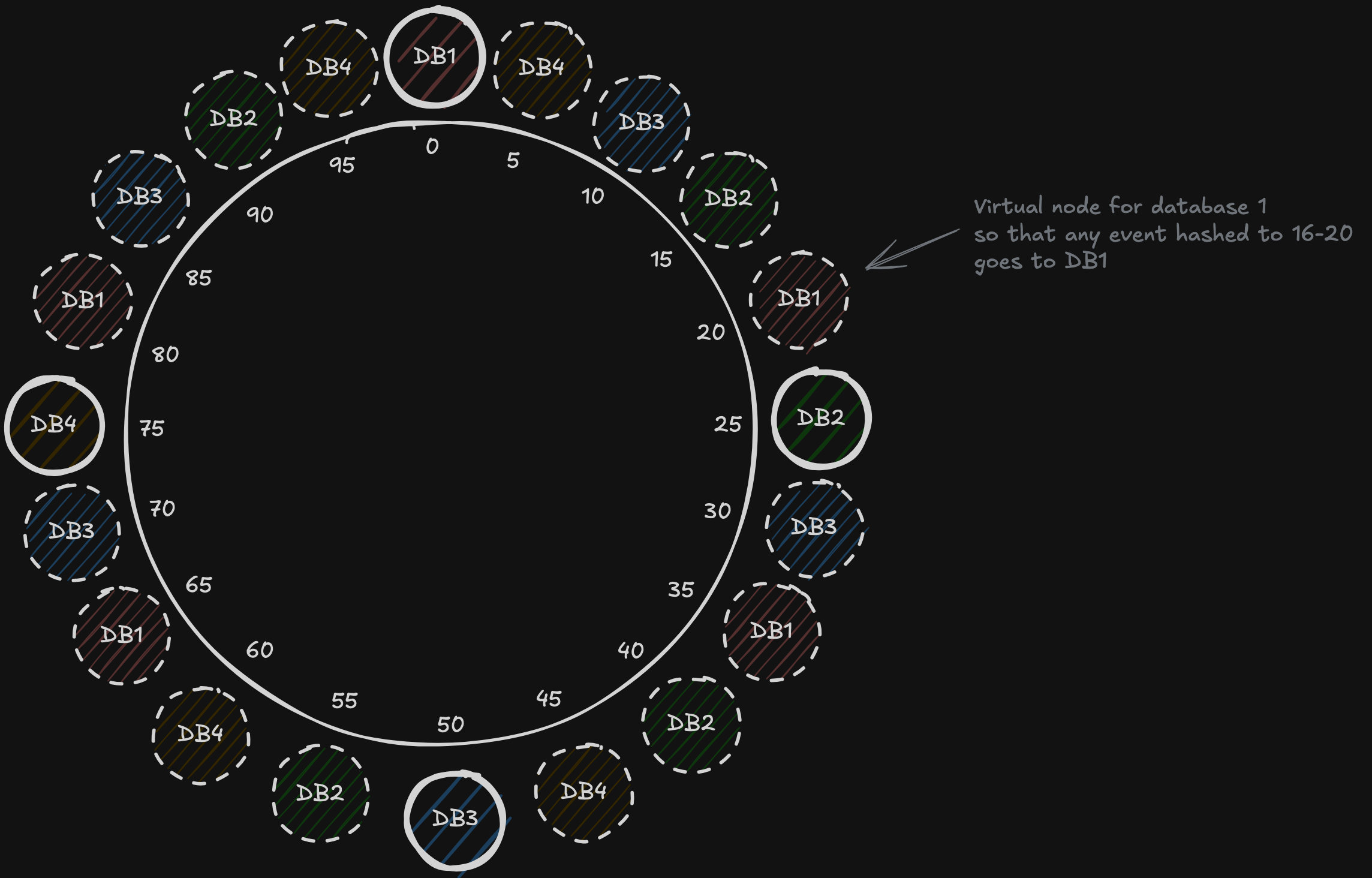
Rebalance the partitions
Ensuring scalability and availability as any distributed system goal
Why Rebalance?
- Unequal data distribution.
- “Hot spots” (too much load on one partition).
- Adding new nodes to handle increased traffic.
How to rebalance ?
Avoid Hash Mod N
This is generally considered an anti-pattern for partitioning.
- The Concept: Assigns keys using the formula (where is the number of nodes).
- The Problem: If you add or remove a node, changes. This alters the result for almost every key.
- The Consequence: A massive amount of data must move simultaneously between nodes, making rebalancing extremely expensive and slow.
Fixed number of partitions
This approach separates the partition count from the node count or data size. There’s always the same number of partitions you determined from the beginning.
- The Concept: Create many more partitions than nodes at the start (e.g., 100 partitions for 5 nodes). Assign multiple partitions to each node.
- Rebalancing: When a new node joins, it simply “steals” a few existing partitions from the current nodes. (It doesn’t create new ones)
- The Trade-off:
- Too small partitions: Too much management overhead, why to rebalance small partitions just because a new node entered the cluster ? this will end up with large number of small-sized partitions.
- Too large partitions: Rebalancing takes too long.
- Used By: Elasticsearch, Riak, modern Cassandra.
Dynamic partitioning
This approach adapts based on the volume of data.
- The Concept: Partitions are not created at the start. Instead, when a partition gets too big (hits a threshold), it splits into two.
- Rebalancing: After splitting, one half stays, and the other half is moved to a different node to share the load.
- The Pros: The number of partitions scales naturally with your data size.
- The Cons: Extremely difficult to do while the database is live. Moving data while reading/writing creates latency and consistency risks.
- Used By: HBase, MongoDB.
Partition proportionally to nodes
This approach ties partitions to the hardware (nodes).
- The Concept: Every node has a fixed number of partitions (Doesn’t mean equal number of partitions).
- More nodes = smaller partitions.
- More data = larger partitions (if node count stays the same).
- Rebalancing: When a new node joins, it randomly splits existing partitions and takes half, leaving the other half alone.
- The Risk: The random splitting can result in unfair or uneven data distribution.
- Used By: Cassandra, Ketama.
Difference between “Fixed Number of Partitions” and “Partition Proportionally to Nodes”
Difference between “Fixed Number of Partitions” and “Partition Proportionally to Nodes” : Fixed Number of Partitions (The “Pre-Sliced” Pizza) Imagine you buy a pizza and immediately cut it into 100 small slices, regardless of how many people are eating.
- 3 People: Each person grabs ~33 slices.
- 4 People: The new person joins. The first three people each hand over ~8 slices to the new person.
- Key Detail: The slices themselves never change. You never cut the pizza again. You just shuffle the existing slices around. Partition Proportionally to Nodes (The “Bring Your Own Plate” Approach) Imagine the rule is: “Every person must hold 10 plates.”
- 3 People: There are 30 plates total on the table.
- 4 People: The new person arrives and brings 10 new plates. Now there are 40 plates total.
- Key Detail: The total number of partitions increases as you add nodes. The new person has empty plates, so they have to go to the others, take some food (data) from their plates, and put it onto the new ones.
| Feature | Fixed Number of Partitions | Partition Proportionally to Nodes |
|---|---|---|
| Total Partition Count | Fixed (e.g., 1,000 forever). | Dynamic (Nodes Partitions per Node). |
| Partition Size | Grows as data grows. If you have 1 TB of data, partitions are huge. | Stays Stable. If you double the nodes, you double the partitions, keeping individual partition size smaller. |
| Adding a Node | Moves entire existing partitions. (Fast metadata update). | Splits existing ranges or introduces new tokens. (Data is physically reorganized into new partitions). |
| Used By | Elasticsearch, Riak, Couchbase. | Cassandra, Ketama (Memcached). |
So simply in Fixed Number of Partitions you don’t add any new partitions once the number determined from the beginning, while in Partition Proportionally to Nodes you add more partition as new nodes added (the number of partitions added for each node is the same ratio so if the nodes usually have 12 partitions any new node added will create new 12 partitions). |
What is the meaning of the word “fixed” in “every node has fixed partitions” for the “Partition proportionally to nodes” technique
fixed number of partitions per node, not a fixed total number for the whole cluster. From the perspective of a single node, it will always have the same number of partitions.
Partition Proportionally to Nodes: The Ratio is fixed. (e.g., “Every node I add will always have exactly 256 partitions.“)
Ration = #Nodes / #Partitions, this ratio is constant
If there is intially 2 nodes each has 200 partitions, then having 3 nodes will increase the total number of partitions to 300
Total number of partitions = #Nodes * #single_node_partitions
In Consistent Hashing a “partition” (technically a Virtual Node or VNode) is just a range of numbers on the hash ring.
- When you have 1 Node: You configure it to have 256 VNodes. The ring is cut into 256 pieces, all owned by that one node.
- When you add a 2nd Node: It also comes with 256 VNodes. Now the cluster has a total of 512 partitions.
In terms of a continuous arc (old consistent hashing)
Think of the ring arc as 1 single VNode
- Start: You have 3 nodes. They pick 3 random points (tokens) on the ring. The “partition” is simply the distance between one node’s token and the neighbor’s token.
- Add Node: A new node joins and picks a new random point on the ring.
- The “Split”: By placing its dot on the ring, the new node effectively “cuts” the existing arc (range) of its neighbor in two. It takes the data from its new dot counter-clockwise to the previous dot.
- The “Split”: To get data for its 256 new partitions, the new node “splits” the existing ranges. It randomly picks points on the ring, “cutting” the ranges currently owned by Node 1.
Can a node handle X slots while another node handles Y slots ?
Now the ratio is not fixed across the whole cluster. Instead, it is a per-node setting
How the “Proportional” Ratio Breaks Down:
- Uniform Hardware: If all your servers are identical, you might give each one 256 partitions. The ratio of Total Partitions : Total Nodes is a flat 256:1.
- Heterogeneous Hardware: If you have some “beast” servers and some “budget” servers, you change the ratio for each specific node.
| Node Type | Capacity | Partitions (VNodes) | Resulting Load |
|---|---|---|---|
| Old Server | Low | 64 | 1x Load |
| Standard Server | Medium | 128 | 2x Load |
| New Powerhouse | High | 512 | 8x Load |