Transclude of Single-leader-followers-replication
Clients only write to the Leader, then the Leaders propagates the updates to other replicas. Clients can read from any node (Leader or Follower) If we had more readers of course we can add more followers and distribute the read load across the available followers.
Pros:
- Very simple to Implement
- Best for read heavy systems
Cons: A single node for writes becomes a bottle neck of the system
Before discussing the problems lets first introduce the ways of replication:
- Sync replication (STRONG Consistency)
The Leader says
OKAYto the client after replicating the data on all the followers. So any time you read the data you will get the latest update. - Async replication (Eventual Consistency)
The Leader says
OKAYto the client after writing the data to himself, after that it starts sending the data to the followers.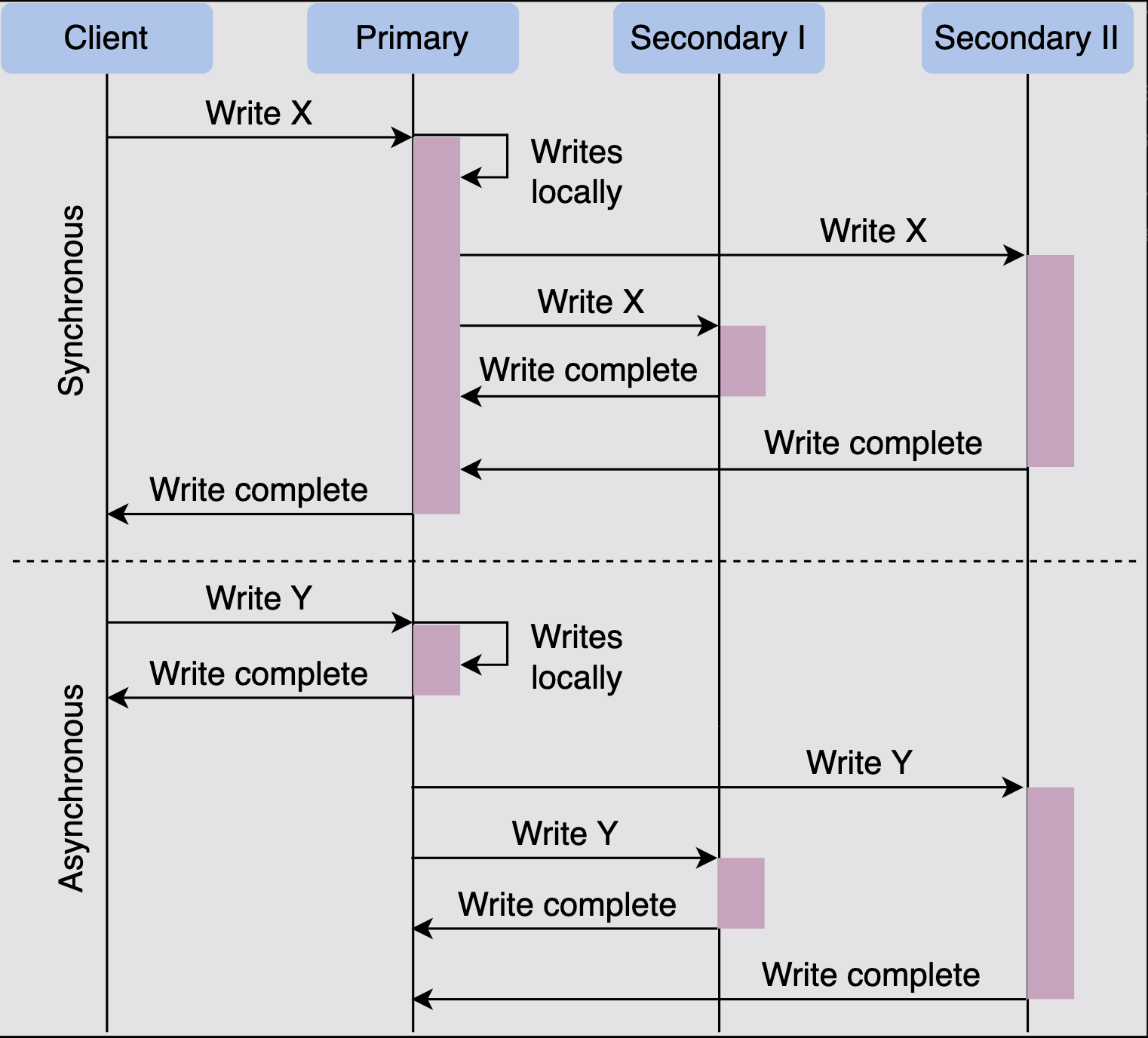
Problems of using Sync way: very slow if one of the followers is really slow the whole operation will be slow too. If one of the followers is down the whole system stuck and the leader waits forever waiting for the response from that follower.
Problems of using Async way: The leader writes data to himself then failed. how the data will be propagated then to other node ? This problem happens only when the Async way is used (it’s reasonable), the leader responds to the client in SYNC way only when all replicas are updated. So when the leader fails after updating himself this will cause data loss, even after a new leader elected the updated data totally goes away as long as the prev leader is down.
What happens when the leader goes down ?
The distributed system algorithm (Paxos or Raft …) detects that and a new leader is elected from the followers.
Another problem is about inconsistency, user read from different replicas may see inconsistent data maybe because the leader goes down before update the replicas or the replicas still not updated yet. (It’s async so there may be some delay)
Which replication way is used ?
leader-based replication is configured to be completely asynchronous.
There are different methods or algorithms used for data replication:
- SBR statement based replication
- WAL write ahead log
- logical replication (row-based)
SBR (MySql) update yourself, write the sql query to the log file and use this logs to update the other nodes by running the same sql query. Simple implementation best used for heavy read systems Cons: causes inconsistencies (Update Task Set Created_At = GETDATE()) this query has different results on the different machiens.
WAL (Postgres, Oracle) write the transaction result (the result itself not any thing else) to a transactional log file and write the log file into disk then update your self, and send this log file to replicas. (take care the log file first need to confirmed written into the disk before the leader even can update himself) That saves the case when the leader goes down, if the leader writes the results into the logs then died, he will reapply them when come back just copying the results into the desk . if not write anything on the logs file, no problem at all (no data corruption).
somehow difficult to implement compared to SBR No sql queries to be executed on replicas just copying the actual data from the logs file into their disks.
To summarize: Unlike SBR, WAL maintains transactional logs instead of SQL statements in a log file, ensuring consistency when dealing with nondeterministic functions. Writing to disk also aids in recovery in case of crash failures. The drawback of WAL is its tight coupling with the inner structure of the database engine, making software upgrades on the leader and followers complicated.
Logical: Unlike WAL, Instead of replicating the actual physical changes made to the database, this approach captures the operations in a logical format and then executes them on secondary nodes.
If an insert or update happens to the leader, the affected row with all its columns values will be captured and applied to the secondary nodes.