telling us where does this spark resource run ?
There’re 3 modes:
- cluster mode
- client mode
- local mode
Cluster Mode:
In general there’s a cluster up and running without spark
 This cluster can be YARN, Kubernetes or any thing. In general there’ll be cluster manager that keep track of the resources, running VMs and Pods and there will be
This cluster can be YARN, Kubernetes or any thing. In general there’ll be cluster manager that keep track of the resources, running VMs and Pods and there will be
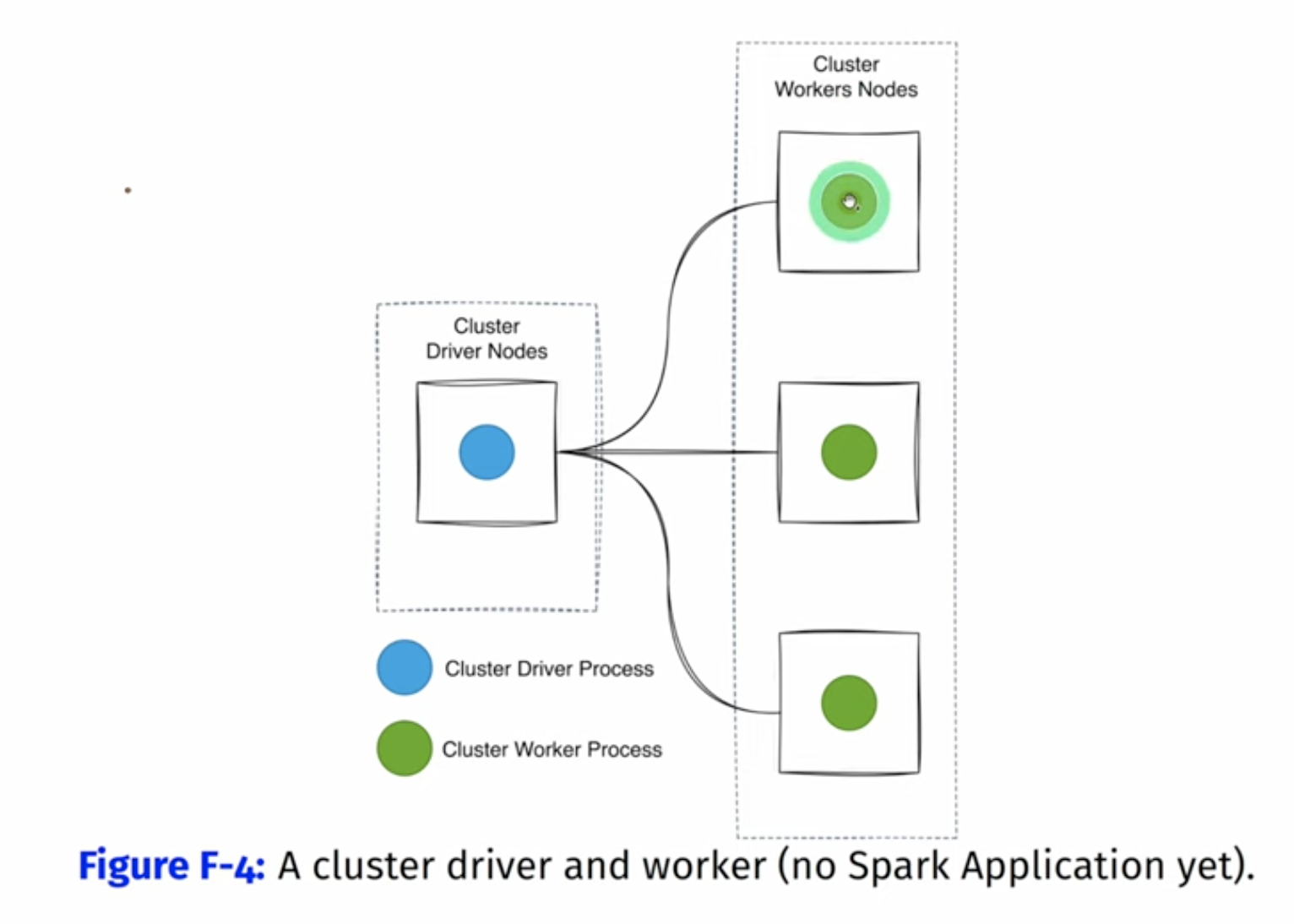
master-slave architecture these are the actual nodes that will run spark.
master driver slave worker
The driver or worker node in a cluster is defined by its running process. A driver node is running what’s called cluster driver process and a worker node is running what’s called a worker driver process. Processes are running as demons.
So we start with normal node, and the running process determines what’s the role of this node (driver or worker)
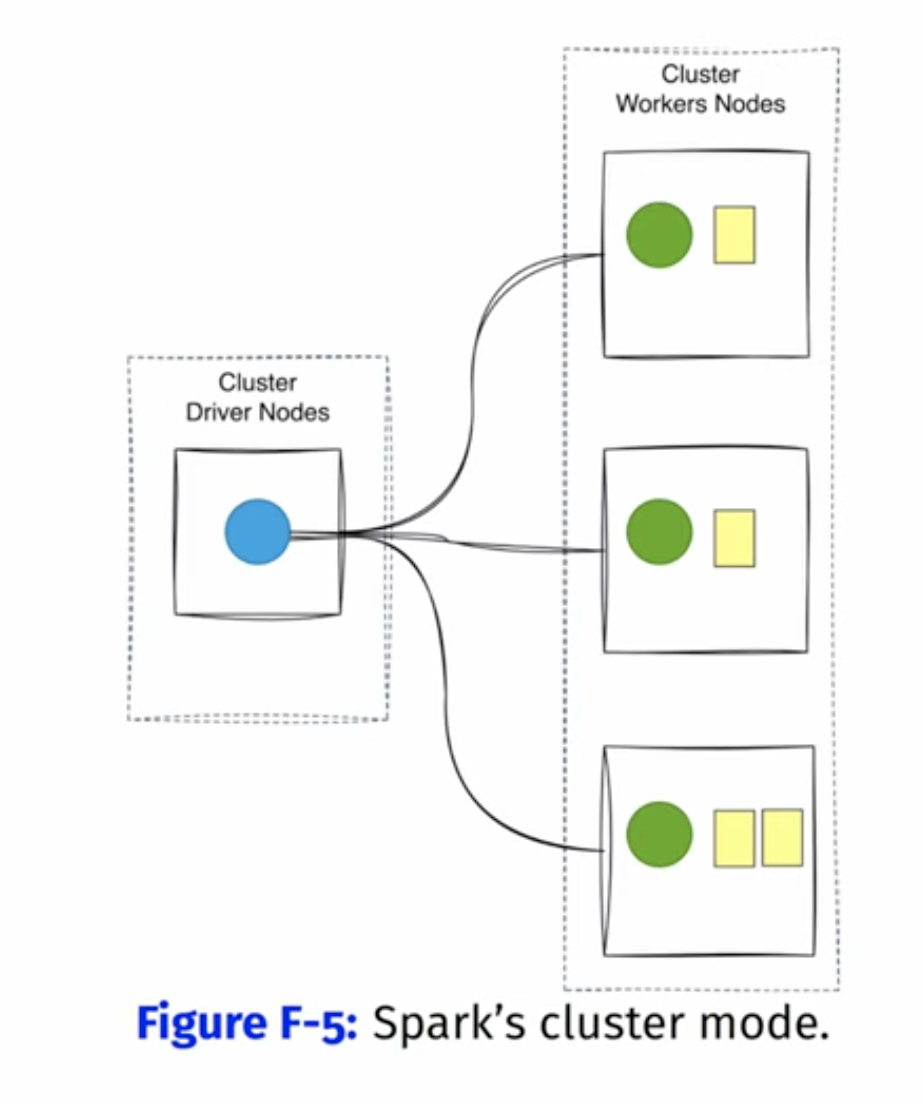
when you submit a pre-compiled JAR or python or R scripts to the cluster, you submit it to the cluster manager and it’s the driver process responsibility to start the spark driver on one of the worker nodes (starting the main function).
spark driver is a normal process running on a worker node and initiated by the cluster driver process.
Then the spark driver process starts to communicate with the cluster manager to request for executor processes and infra holding (memory, cpu, … ) again the executors are normal processes running on worker nodes within the cluster
Note
Spark driver process and executor process may run on the same worker node
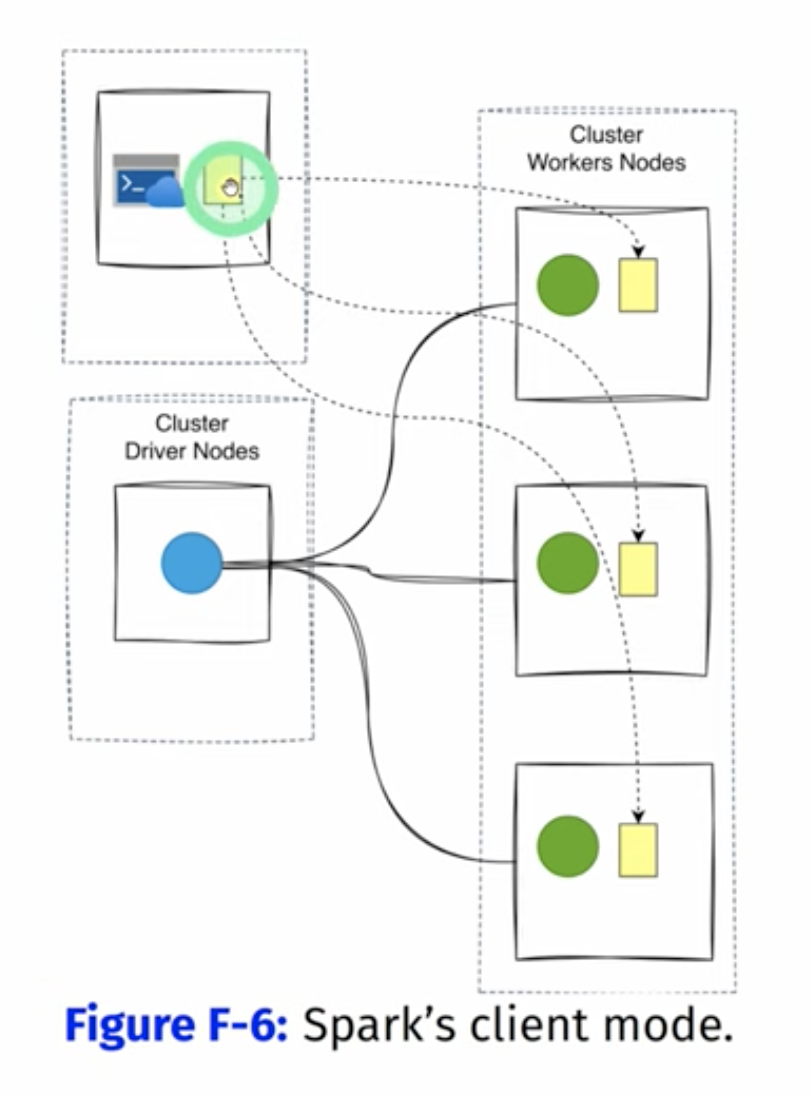
Client Mode:
Just split the spark driver process out of the cluster management, there’s still a cluster with its driver and worker processes but it meant now to just handle the spark executors
and it’s job another external machine to take care of the driver and it’s responsibility to submit the tasks to the cluster.