Name conventions
Server ⇒ Machine / Process / Node Other Literature Server to be Process or Machine but Node is the term we used
Consider a single CPU, single Core, and single Threaded server contains a chat app . This chat app is only a single chat room and all the users can connect to that chat room and the application is responsible to forward this message to all other users.
The clients connected to the server through TCP connections and utilize certain socket for each client. The server maintains a state ie. the sockets to which the clients connected. So a message arrives the server the thread starts looping through the server and list of sockets and send the message to socket’s client.
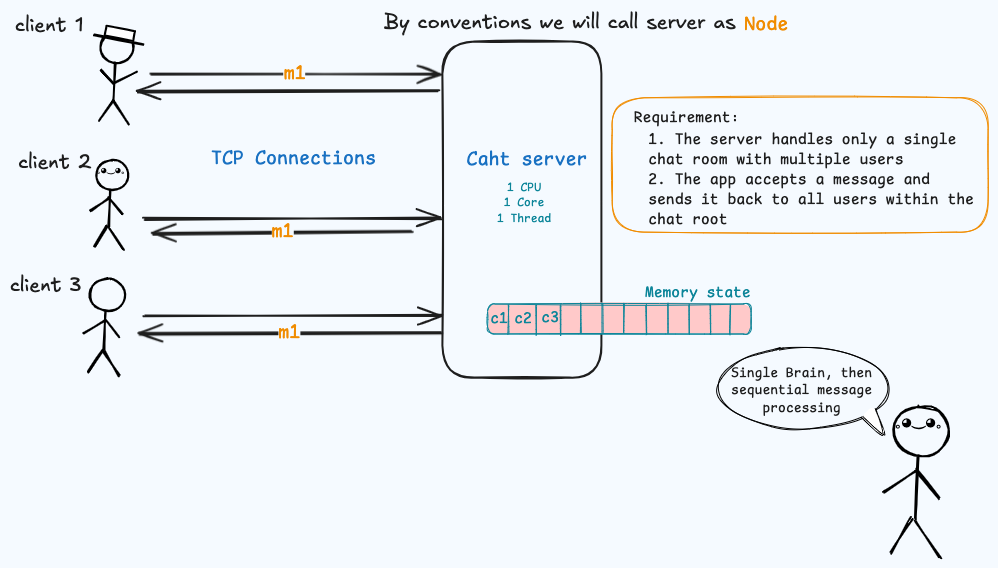 the messages are processed sequentially, the server can handle only a single message at any time. there’s no concurrent processing. So any all messages will wait in queue until the current message finished.
the messages are processed sequentially, the server can handle only a single message at any time. there’s no concurrent processing. So any all messages will wait in queue until the current message finished.
Not imagine that the number of user increased to a limit that the server became really slow. we need to scale the server
- Handling more clients using the same hardware
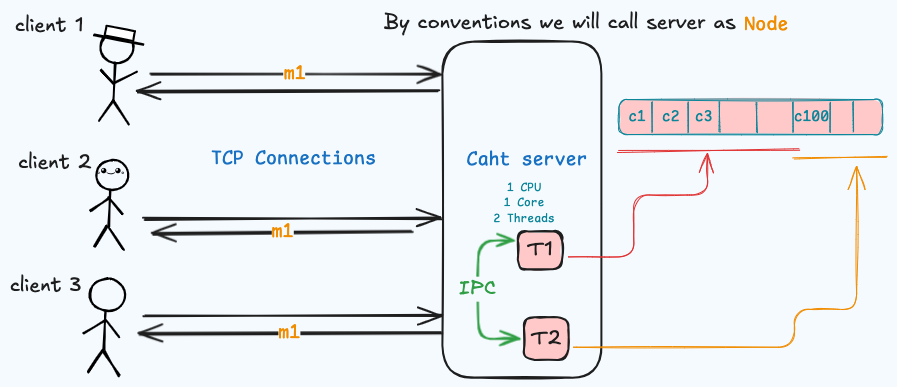
- Serving more messages Let’s scale up the server to have multiple threads and split the workload between them, so thread_1 is responsible for the sockets from 1 to 100 and thread_2 from 101 to 200 and so on. (Preemptive scheduling) the cpu schedules the execution of threads and switch between them.
This approach will enhance the node performance but how thread_1 will send the message to the clients on thread_2 there must be some communication between the 2 threads.
TIP
state is the data stored within the Node and the application cares about
As the 2 threads are on the same machine then the communication can be done through Interprocess communication using a shared memory portion to interchange messages.
This communication type is said to be highly reliable and synchronous, there may be no failures at all in this communication between the 2 threads , they are on the same machine.
Things happen within the same machine are sync and atomic, you know the result immediately. The start time and Complete time of specific operation as small as an instant operation.
What meant by SYNC operation ?
Operations on the same machine are thought about to be synchronous and have atomicity meaning immediately I will know if the operation completed or not and got the results.
This simplifies the Programming model and Error models
As the number of users increases, we need to scale up the server to have more and more resources (CPUs and memory) and then no way to scale up further !!!! (imagine a 1000CPU machine and there’s more users coming, what a mess!)
Scaling up the same server is called Vertical scaling while deploying the server on different many machines is called horizontal scaling.
The next solution is to split our application across multiple machines (Distributed System).
What about the state now ?
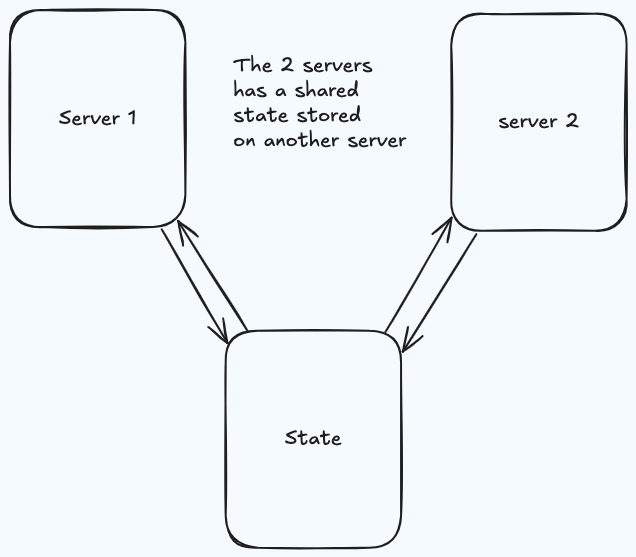 first idea is to have a
first idea is to have a shared state stored within another node like database server
and the 2 application servers calling it to update or read the state.
This approach introduces 2 problems:
- what if the state is so large that can’t fit in a single machine ?
- what if the application is so chatty that the network bandwidth is very consumed.
HINT
An idea to solve this, what about split the database/cache (state storage) into many nodes (another distributed system) 💡
Lets’s split the state between the servers and the machines talk to each other through network
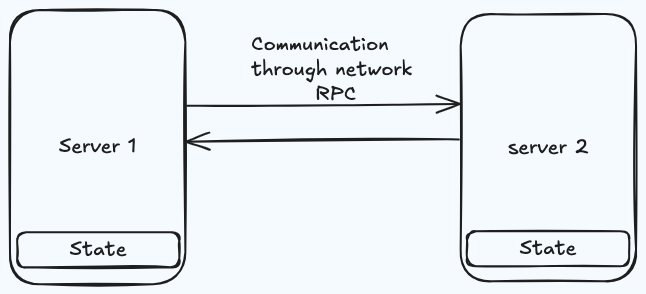 Compared to the single server solution, now there are many differences:
Compared to the single server solution, now there are many differences:
- State is splitted
- Communication between nodes become
Async - No atomicity (no instant operation execution), new failures appear
Atomicity
On a single machine you feel like the operation is done instantly, you see the start and end times as a single time (SYNC + Atomic) operation. While when you have an operation done through a network you fell the ASYNC execution you get the result of the operation after a while when all the network operation done and see the result (Fail or Success).
Starting from this point we can define the distributed system:
Distributed system is the separation of Compute and State or State only or Compute only into different nodes and communicate through unreliable (can fail in more ways than the SYNC communication) communication channel Async communication and has less predictability than if they were running on the same machine.
- Compute means the single node CPU/Core
- State means any data store important to the application, data can be memory/disk/database any thing used by the application deployed on the server
- Communication means the network between the nodes
2 reasons to have a distributed system:
- Scalability (serving more traffic/users, storing more data) is about capacity
- Availability
- Fault tolerance “قدرتي علي التعامل مع الfailures مش مقاومة الfailures” for example when some machine goes down the other up machines can handle the requests until the main machines starts again.
- Consistent Latency like according the SLA the readers should read data within x seconds, so replication of data will be very good for this case.
- Durability Availability of data under failure
TIP
In distributed systems by Node’s state I mean the data that’s meaningful to the application deployed on the server
Stateless vs Stateful distributed systems
Any Node consists of
ComputeandStateBy Compute means the application/service deployed on the server By State means the data important to the application
As we said DS is the separation of Compute and State or one of them through unreliable network
- stateless: separation of compute while maintaining a shared state even on another server it’s considered a shared state accessed by all compute nodes
- stateful: separation of state
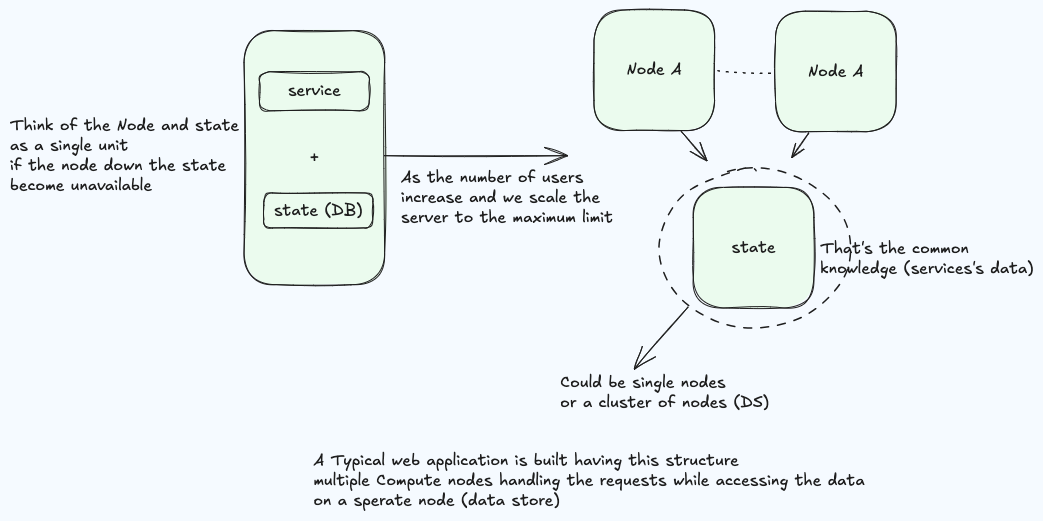
Stateless
We are constrained on compute (limited cpus/cores/threads for a single machine) so if we want to scale the node up we need another compute node while the state is put on another shared server accessed through the network.
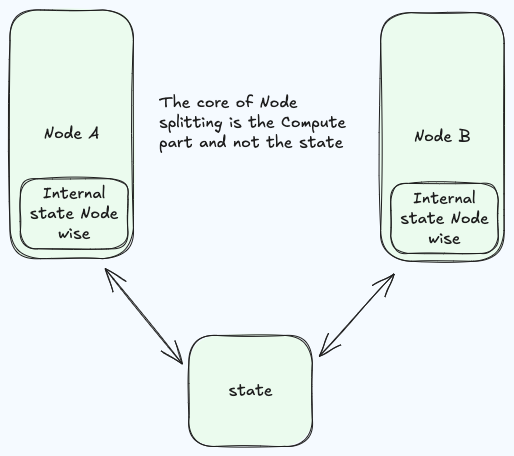 Each compute node has an internal state , it’s not important to the service or the application deployed on the server but it’s important to the server itself and not the compute part so it’s not a
Each compute node has an internal state , it’s not important to the service or the application deployed on the server but it’s important to the server itself and not the compute part so it’s not a COMMON KNOWLEDGE
By Common knowledge we mean the state that’s important to any compute node of the service
The state could be a single database server, cache server, or any data store. Also it can be a single server or a fully distributed server (Cluster) but behaves to the clients as if it’s a single server.
This type of distributed servers is called STATELESS DISTRIBUTED SYSTEM, and is considered the simplest distributed system.
EXAMPLE:
Stateful DS
The database cluster from the previous example is a great example of stateful distributed systems
Rule of thump !
We can’t totally prohibting failures, but under failure we a node is down we can still serve data

Fault Tolerance
It’s not about preventing failures, but how to make still still functioning even incase of failures (how to deal with faults).
1. Node Failures
The Node itself became down, or STH happened makes the node down from the client’s perspective (sth happened on the datacenter) a) Fail Stop / Hard Failures The node up or down, node crash
b) Grey Failures (byzantine failures) → the hardest part in DS Node is up but mis-behaving (slower than usual, wrong response)
2. Network Failures
a) Fail stop The node can’t see the network any more or the network itself goes down
b) Grey Failures byzantine failures a very concerning use case of it “Network Partitioning” where some nodes see each others and they imagine all other nodes are down while they are up and performing
so the nodes are separated into different groups while the groups can’t see each others.
Should we design the system to be resilient against all those errors ?
Should the system be operate any circumstance ? Is that a reasonable goal ? Depending on the system requirements, you choose the tradeoffs You needn’t to prevent failures but being able to recover from it
okay as a system I will be resilient against some failures but I will allow other types to happen then I will recover from them quickly
Consensus (Distributed consensus) is the process to maintain a state (common knowledge) between nodes.
Conclusion:
- The difference between stateful and stateless Distributed systems is the existence of state we need to maintain between the different servers.
- State means some data we need to maintain between nodes
- Fault tolerance means that the system should be able to continue operating even in case of failures
- The system provides 2 things to its users:
- As a system I will tolerate X failure
- Consistency guarantees
Definition of Node in distributed systems:
A machine behaving as if it’s single core single threaded, while it’s single core or single threaded or not (It’s about the how it behaves no about how it’s internally operating).